【エンジニア 情報収集】mercari tech conf 2018参加メモ
mercari tech conf 2018に参加したので、そのメモです。

10:00
オープニング
濱田優貴氏

今年のテーマは「Evolution」かっこいいです
基調講演
名村卓氏

「技術力は創造性」
2020年までに1000人のエンジニアをとる
技術への投資は惜しまない
エンジニアの数
120から350人に
組織が大きくなると、、、
スピードの低下
裁量の減少
思想の衝突
が、問題になる
↓
同じ思想で開発から、
多様な思想で開発をする
即戦力を集めるのは難しくない
だからといって、
即戦力ばかりにこだわるのではなく、
優秀な人材が育つ組織を目指す
組織のための技術戦略
小さな決断が常に起きているようにする
マイクロサービスの導入
マイクロサービスはかつてはバックエンドの技術。今はフロントエンドも。
マイクロデプロイ
マイクロナイズすると、
レジリエント(耐性)
ができる。
一つの不具合が、他の部分にまで波及していまう。そのためにマイクロナイズして、対応できるようにしている。
Dr. Mok Oh 氏
メルカリUS CTO

曾川 景介氏
メルペイCTO
信用と創造について
メルペイ
メルカリの金融事業
CtoCサービスでは信用が重要
2者間での取引は難しい
↓
エスクローの導入
経済学的にいえば、
欲求の二重の一致がなければ、
取引は行われない。
価値交換を通じて、信用を創造する

メルカリx
(社内向けの取引サービス、研究開発用のサービス、一般公開予定はない)
リスティングとエスクローをプロトコルとして、価値交換をしている
メルカリ社員さんとランチ
メルカリUKはPHPが基本
・BOOTH
We are the machine learning team!
リアルタイム物体認識アプリ(試作中、今後リリース予定)
インフラGCP
Tensorflowでモデリング
アルゴリズムはいろいろ
MacとかiPhoneのバージョン認識まではまだ。ただし、教師データがあれば解決できると見込んでいる。
セッション
13:00
Microservices Platform at Mercari
中島太一氏
モノリシックなシステムから
マイクロサービスへ
→サービス拡大のため
アーキテクチャにあわせて、
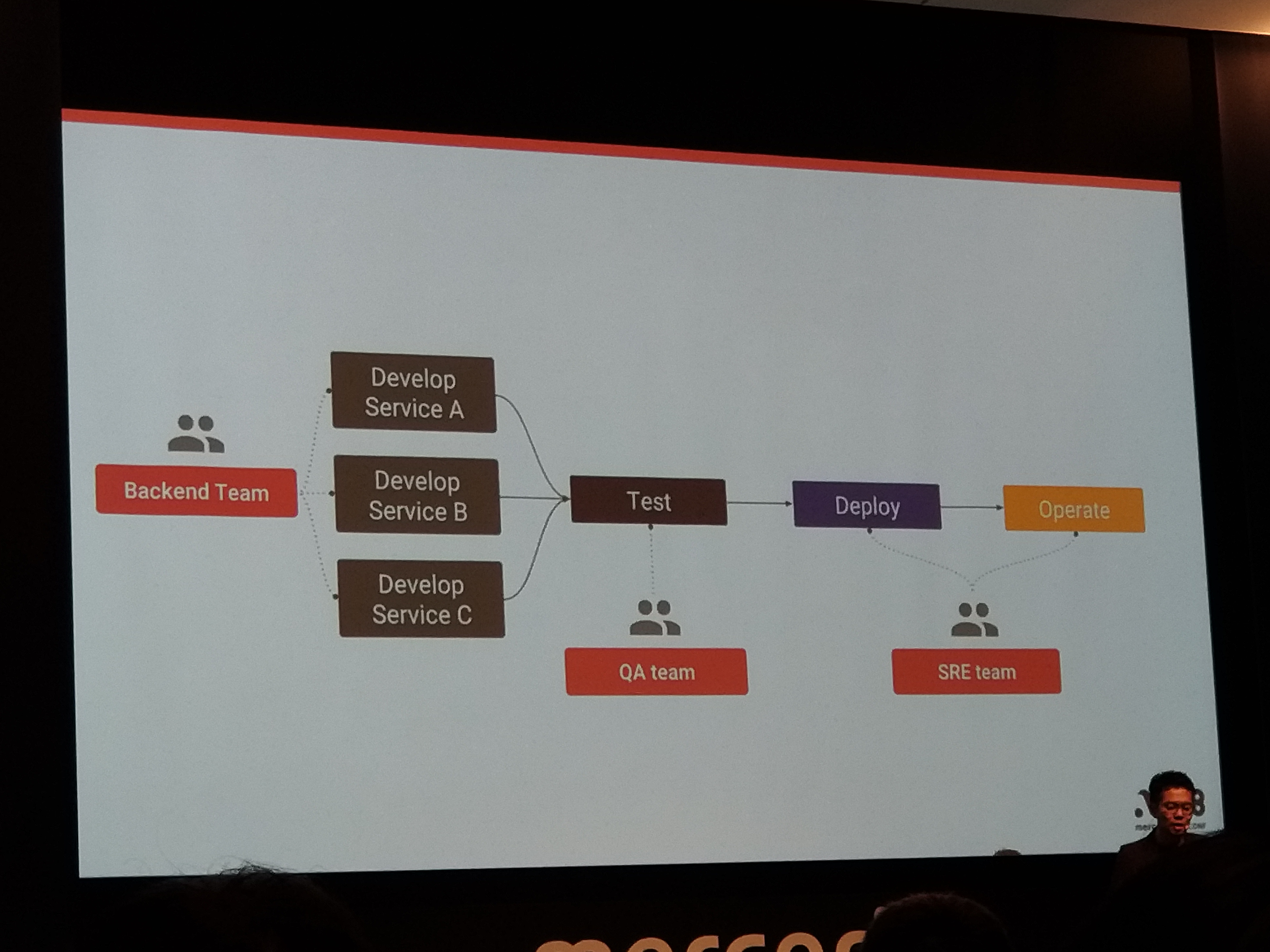
組織のデザインをする必要がある
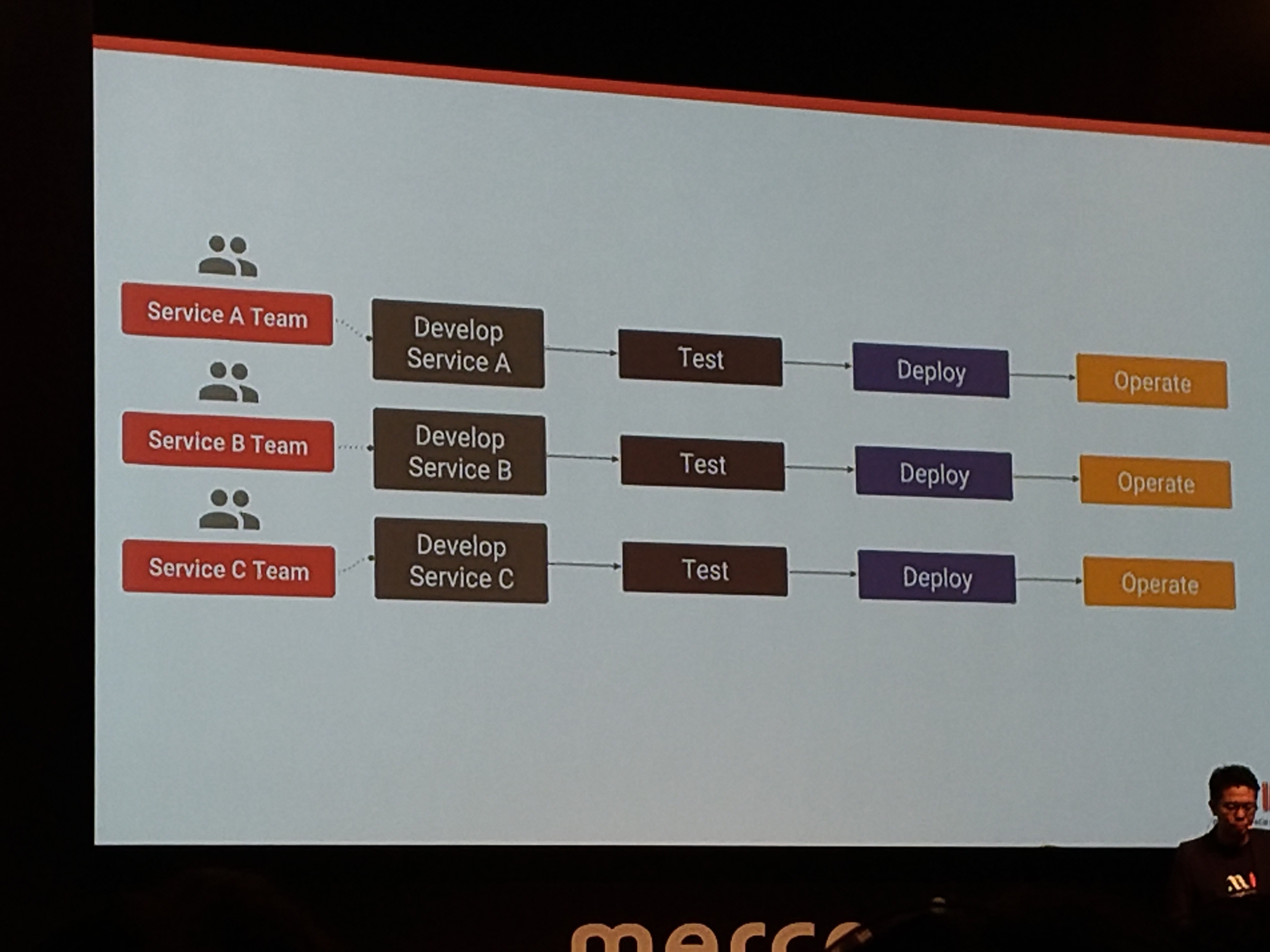
理想はマイクロサービスごとにチームをわる
SWE、SET、SRE
バックエンド
これまでPHP
マイクロサービスは
Goで。
インフラプロビジョニングサービス
マイクロサービステラホーム
従来のmonolithicな構造
マイクロサービス
レポジトリ内にはサービス毎にディレクトリがある
chaos testing
13:40
Mercari ML Platform
中河宏文氏
メルカリMLプラットフォーム
内製のプラットフォーム

kubernetesを利用している

各要素について
プロメテウスというOSS
コンテナにすると、依存関係の解決が簡単
モデルは最大数十ギガバイトのファイルサイズのものもある。
モデルをロードするたけで、メモリを数ギガ。
将来的には
エッジコンピューティング
→スマホでリアルタイム画像検知

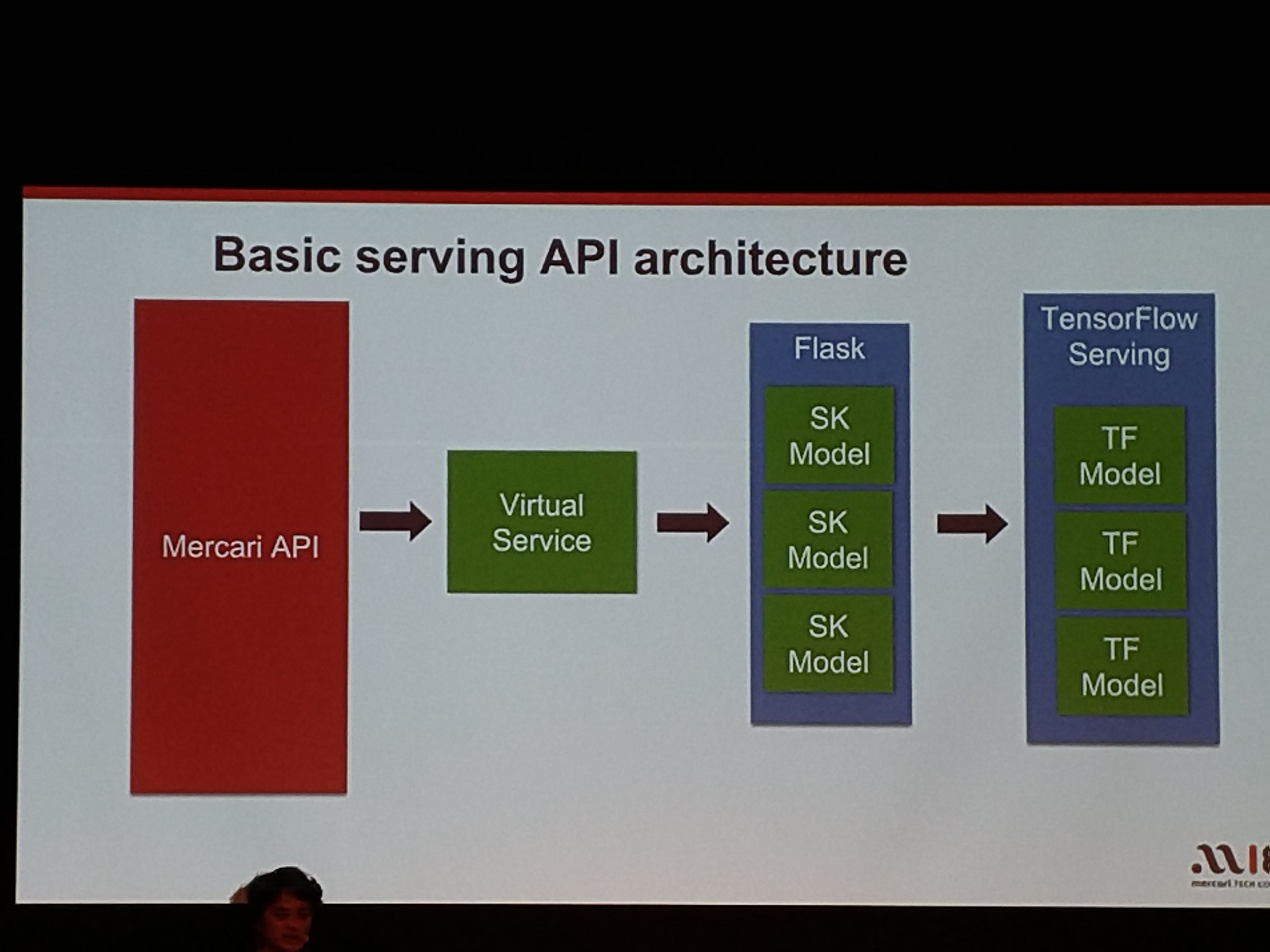
API構造。Scikit-Learn(Pythonの機械学習ライブラリ)とかもつかっている。
数千のモデルの運用
高度な自動化が不可欠
Booth
量子アニーリング
GPUよりも30倍速い
D-Waveの量子コンピュータをAPI的に利用。ハードウェア次第

14:20
Android at Scale
Israel Ferrer Camacho氏
モノリシックをモジュールに
エンジニアの数が増えると、モジュールごとに責任を持たせて開発したほうが効率的
時間短縮になる
Coreに共通処理を
アプリケーションに関係なく利用される機能はコアモジュール部に入る
このようにして、
クオリティ
一貫性
再利用性
を高めた。
これは、長期的なエンジニアリング文化の変革
コーダー的な責任から、エンジニア的に責任へと変革が求められる。
エンジニアにとって、コードレビューが大切。
エンジニアはつねにさまざまな解法を考え、パフォーマンスを重視して、質に気をつける必要がある
エンジニアには、多くの仕事がある
このようなエンジニアになるには、
提案を書く
協業する
ガイドラインを書く(ひとは忘れるから)
チームで訓練をする
ペアプログラミングをする
ペアプログラミングをやっている2人とも学びがある
コードレビューをする

エンジニアとコーダーの違い。エンジニアがやるべきことはたくさんありますね。
15:00
ViewControllerのTypeErasureを実装する
齋藤 暢郎氏
・技術的負債
メンテナンスコストの増大
既存コードのためのノウハウの悪影響
・技術的資産
機能が正しくうごく
再利用可能
追加機能なし
コードにアクセスできない
→たとえばLinuxとか
解決
フレームワークを分ける
責務を分けて負債を資産に変換
そのために、型をうまく定義する
16:00
Search precision tuning with query rewriting Subtitle: Internship at mercari
八木 悠斗氏
検索の最適化
→ノイズの除去の為に行う
情報型検索
検索語がどんどん変わっていく
→一般化が困難
取引型検索
検索語が短命
ユーザの意図を読み取るのは難しい
検索ログから、ユーザ意図を探ることができる
ランク学習をさせている
量子情報時代の通信技術:量子インターネット
永山翔太氏
量子インターネット
量子エンタングルメントを利用した通信をおこなう
概念
量子エンタングルメントとは?
BとCはたがいに量子もつれ状態にあるとき、BがわかればCの情報がわかる(その逆も成立し、Cの情報がわかればBの情報がわかる)。これはどれだけ距離が離れていても成立する
このとき、AとBが情報のやりとりをすると、BとCは量子もつれ状態にあるので、AがBへ渡した情報はCに伝えることが可能である。
A Bー(離れている)ーC
将来の通信の姿

16:40
Web Application as a Microservice
杉浦 颯太氏
変更に強い柔軟なアーキテクチャ
トレンドへの追従
開発チームのスケーラビリティの向上
エンジニアの増加に耐えるアーキテクチャ
各チームの技術選定を自由に
ひとつの巨大なリポジトリ
→モノリシックサービス
これをマイクロサービスにどう移行するか??
いきなりは無理なので、
一つのモノリシックサービスと4つのマイクロサービスで並行運用する
バックエンドのマイクロサービス化は、フロントエンドにどんな意味があるのか?
17:20
数十億規模のデータと機械学習で描く未来
山口 拓真氏

メルカリの機械学習の歴史
数十億規模のデータセットと考えると巨大
ただし、ログはデータとは考えない
メルカリが機械学習をやるのは、流行りだからではない。人間系で行う作業として、限界が来ているから。
安全な売買の機械学習
kaggleで、価格決定アルゴリズムのコンペを開催。
メルカリが機械学習がやった取り組み
-重さ推定
-画像で商品検索

Software2.0とSoftware1.0のちがい
がっちりとロジックを組むよりも、データを与えて経験則的にアルゴリズムを編み出していくのがSoftware2.0という感じでしょうかね。この流れを読むことは非常に重要だとおもいましたね。

山口氏が最初にやったこと
Software2.0的
とはいえ、引き続きSoftware1.0は必要
autoML
機械学習が機械学習モデルを作る
そして、人間が作ったモデルよりも精度がよい
18:00
メルカリにおける検索サービスの現在と未来
杉木 健二氏

検索チームの取組み。DB操作が肝な感じですかね。
メルカリのユニークさ
C2Cサービスであること
出品点数10億突破
マスタカタログデータがほぼ存在しない
関連キーワードの生成
クエリの自動補完機能
Solr をベース
C2C独自の検索事例
クロージング
メルカリはテックカンパニーを目指す
・感想とまとめ
現在の日本のWeb、IT系企業で筆頭的に技術があるといわれているのが、Preferred Networksとメルカリです。メルカリは2013年にできた企業なので今年で創立6年目。まだ若い企業です。楽天、サイバーエージェント、DeNAなど、古株のIT企業はあります。しかしながら、それらよりも技術力のある企業としての印象は世間一般的に強い気がします。今回Tech Confに参加させていただいて、この理由ははっきりとわかりました。基調講演でありましたが、メルカリは「テックカンパニー」目指しているということです。テックカンパニー、つまり、GoogleやFacebookのような最先端のIT技術を駆使して課題解決をする企業です。
2020年までに1000人規模のエンジニアの雇用を目指しており、それも、単に即戦力人材の確保ではなく、優秀な技術者が育つ組織づくりを指向しているということです。
技術への投資は惜しまないと言われていました。それはヒトとモノの両方です。会場でインド人っぽいひととすれ違ったと思えば、今日のネットの記事で、インド最高学府の学生を採用しているという記事を見つけました。
R4D(Design,Development,Deployment and Disruption)という最先端の研究開発に取り組みを行う組織もメルカリは持っていて、ブース発表では量子コンピュータで計算した結果をPepperに入力して制御を行うデモを実演したりと、単なるフリマアプリで利益を上げるWeb会社の姿ではありませんでした。最新技術を研究開発するテックカンパニーの姿とはこういうものなのだと思いました。
研究開発したことが実際にビジネスに結び付くかどうかということはさておき「技術への投資は惜しまない」という姿勢は紛れもなく本物で、まだ創立の浅いIT企業ながら業界をけん引するほどの存在感をもつほどになった理由が十分に理解できた気がします。
お金とモノと人がそろって、技術開発は加速するのだということがよくわかった気がします。それらのどれかひとつがかけただけで、100進むものが10くらいにしかならないことがあるというのも何となくわかった気がします。
しかしながら、メルカリはテックカンパニーになるべくしてなったのだとも思いました。ユーザからフリマアプリを通じて提供される大量の商品画像データというのは、サービスの自然な導線上にあるもので、結果としてそれが画像分類技術を醸成するための環境となっているからです。さながらGoogleフォト的な感じです。流行を追った機械学習ではなく、必要に迫られた機械学習なので、切実であるし、否が応でも研究開発せざるを得ない。うまく世間の技術トレンドにのったサービスをやっていたというのも、テックカンパニーたらしめる理由になったのだと思いました。(じつはテックカンパニーになることを狙ってフリマアプリサービスをはじめたのかもしれませんが。)
では、テックカンパニーになるにはどうしたらよいのかを何となく考えてみました。
機械学習
メルカリの例のとおり、データが大量にあることで、十分な学習をさせることができるものがあれば、なれるかもしれません。ただし、メルカリの持っているユーザからの商品画像データは2018年10月時点で10億ほどなので、画像データのAI系でメルカリクラスのものをつくるならそれくらいのオーダーのデータが必要。このクラスを狙うとなると現実的には、何らかのCtoC向けサービスやユーザからデータを得られるサービス等をやっているところになるのかなと思いました。つまり、大量のデータを収集するのが容易なサービスをやっているところがよいということです。そのクラスを狙わないなら、いろいろやりようはあるのかなとも思います。
他の技術
たとえばメルカリはxR(VR,MR)にも着手しているようですが、そういったものなら機械学習ほどの難易度はなさそうな気がします。ただ、ヒトモノカネをかけたところがいちばんいいものを作るのではないかと思います。たとえばxR系はマスメディア系がもっている雰囲気にあっている気がします。
最後に、機械学習のブースでiPhone6とiPhone6sをどうやって判別するのかと尋ねたところ、データがあればなんとかなると言っていました。それくらいのデータを集めて、判別までやってしまう技術があるメルカリはやはり現時点で日本を代表するテックカンパニーなのだと思いました。
追記
カンファレンススライドはこちら
https://speakerdeck.com/mercari